
Edge AI is increasingly moving complex machine-learning models from the cloud into small, power-constrained devices, including wearable health monitors. This post shares five lessons from taking a deep learning arrhythmia classifier from Python notebooks to an edge-AI accelerator running on a Zynq-7020 FPGA on the Xilinx PYNQ-Z1 platform.
The project goal was simple to state: accurate real-time arrhythmia classification on a compact, low-power FPGA that could, in principle, be integrated into a wearable ECG system.
In machine learning it is hard to judge a new model in isolation, so community benchmarks have become essential. In ECG (electrocardiogram) arrhythmia detection, this typically means the MIT-BIH Arrhythmia Database combined with the AAMI EC57 heartbeat categories. The Association for the Advancement of Medical Instrumentation (AAMI) defines five main heartbeat classifications in the ANSI/AAMI EC57:1998/(R)2008 standard for automated arrhythmia detection normal (N), supraventricular (S), ventricular (V), fusion (F) and a rarely used “unknown” (Q) class. Using this dataset together with the AAMI EC57 labeling scheme aligns the work with most of the ECG arrhythmia literature and makes it possible to compare performance across studies in a meaningful way. In this project, the deep neural network was trained on multi-beat MIT-BIH windows and evaluated on the four primary AAMI classes (N, S, V and F).
The rest of this post distils that journey into five lessons that apply broadly to edge AI devices, not just ECG classifiers.
For ECG arrhythmia classification, clinical insight and knowledge of the signal are as important as the choice of network architecture. Cardiologists emphasized that many arrhythmias cannot be reliably identified from an isolated beat, temporal patterns between consecutive beats are often essential for correct classification.
This led to several concrete design choices:
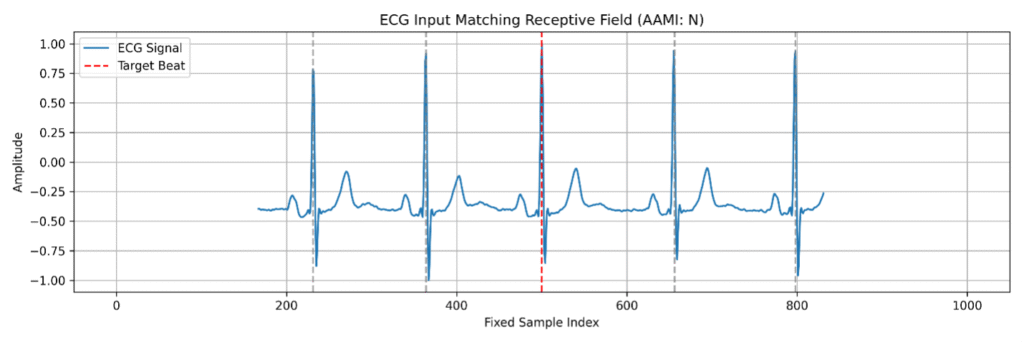
The lesson is simple: the right input representation is not a detail to fix later. If the data does not reflect the real clinical problem, neither the network nor the FPGA implementation will solve the right task.
On edge AI devices, the architecture that is convenient for training is not necessarily the architecture that should run on the FPGA. Temporal Convolutional Networks (TCNs) use stacks of 1D convolutions with dilations to cover long time spans efficiently, while more conventional 1D CNNs (Convolutional Neural Networks) typically rely on dense convolutions and strides. In this work, a non-causal TCN was deliberately chosen for training because its dilated structure provides rich temporal context and stable optimization, and after training the entire model was structurally reparametrized into an efficient 1D CNN with carefully chosen strides that preserves the same computation for the central output.
During training, the non-causal TCN:
Once the TCN is trained, its receptive field is analyzed and only the single computational path that influences the central output is kept, yielding an inference-optimized CNN that:



This “train heavy, deploy light” pattern fits edge AI well, but it is not the only option. What matters is choosing an architecture that both learns the right signal and can be implemented efficiently on the target platform. In this case, a TCN with a clearly defined receptive field made it possible to collapse the dilated structure into a stride-based CNN that computes the same central output with far fewer operations. Even if you never restructure the network, it is worth thinking about these hardware implications when you select the architecture in the first place.
On small FPGAs and other edge AI devices, 32-bit floating points are rarely viable; quantization is not optional. In this project, quantization was treated as a first-class design constraint using quantization-aware training (QAT) with Brevitas, with the trained model exported via Open Neural Network Exchange (ONNX) into Xilinx’s FINN framework.
Several practical consequences followed:
These results illustrate the importance of planning for quantization from the beginning. By integrating quantization-aware training with a deployment framework such as FINN, the model learned in software can be translated directly into an efficient FPGA implementation without a late-stage accuracy penalty.
The final CNN was co-designed with the FPGA implementation rather than treated as a separate, fixed object. The PYNQ-Z1 served as the prototyping and benchmarking platform, but the accelerator was intentionally designed to be as small as possible, prioritizing portability to smaller edge FPGAs over exploiting the full resources of the board.
Using FINN as the deployment framework, the hardware implementation of each layer can be configured through parallelism parameters such as processing elements (PE) and SIMD lanes. Increasing these parameters increases the number of operations executed in parallel, reducing latency but also increasing FPGA resource usage. Conversely, folding allows computations to be time-multiplexed onto fewer hardware units, trading higher latency for lower resource consumption. This creates a design space where throughput, latency, and resource utilization must be balanced.
Using this framework, several hardware-aware design decisions emerged:
On the implemented PYNQ-Z1 design, the inference-optimized CNN accelerator achieved:
To place these results in context with prior work, the table below summarizes latency, power, and resource utilization across publications with hardware implementations.
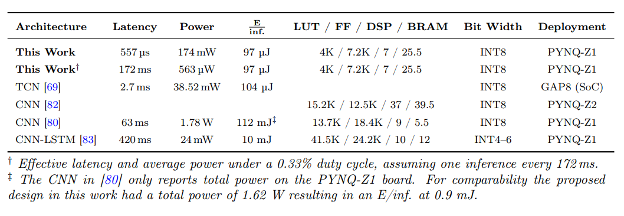
These results highlight the benefit of treating the neural network and the hardware implementation as a single design problem. Using FINN to explore the hardware design space made it possible to systematically trade parallelism, resource usage, and latency, resulting in highly energy-efficient inference on small edge FPGAs.
For a wearable ECG edge AI device, test accuracy alone is not enough. The evaluation framework in this work deliberately combined machine-learning metrics with computational, implementation, and power metrics to reflect the full system behavior.
On the ML side, the following were tracked:
On the hardware and system side, the evaluation included:
Looking at these metrics side by side made the real design trade-offs visible. It showed not just whether the classifier worked, but whether it worked with the robustness, speed, size, and energy efficiency needed for a credible wearable edge-AI system.
Deploying a deep learning ECG classifier on an FPGA turned out to be less about a single breakthrough and more about aligning many details: clinical insight, data preparation, receptive-field design, a train-heavy/deploy-light architecture, quantization, and hardware-aware mapping. The common thread across all of these steps was a focus on the final deployment target. Designing for edge deployment from the beginning meant that constraints such as limited resources, tight energy budgets, and real-time operation shaped decisions throughout the process, not just at the end. Together, these choices enabled edge-AI inference that is both accurate and energy-efficient, with latency and power figures compatible with future wearable ECG systems.
Although this work focused on arrhythmia classification, the same five lessons extend well beyond this application: start from the domain, separate training and deployment architectures when useful, treat quantization as a first-class design constraint, co-design the network and its hardware, and evaluate success at the system level rather than through a single accuracy metric. When these principles guide the process from the start, complex models can move from notebooks to real devices in a way that is both practical and trustworthy.
Even Eide Hansen works with FPGA development, embedded systems, and edge AI. His work spans FPGA-based system design and mixed software/RTL verification using Renode-based co-simulation. This post is based on his award-winning master’s thesis, Deep Learning for Real-Time Arrhythmia Detection on Edge FPGAs in Wearable Devices, which received FPGA-forum’s prize for best FPGA-related master’s thesis in Norway.



